Nell'ambito della traduttologia i corpora vengono utilizzati in maniera principalmente contrastiva, paragonando cioè dati ricavati da due (o più) corpora o sottocomponenti omogenee di un corpus. Una prima categorizzazione riguarda quindi la natura del o dei rapporti tra le diverse componenti di un corpus "contrastivo", mentre una seconda riguarda i criteri che hanno portato alla selezione dei testi costituenti il corpus per ciascuna componente.
Il confronto può avvenire tra due tipi di testo della stessa lingua (come è il caso dell'ECC Project, che mette a confronto testi tradotti e testi originariamente composti nella stessa lingua), oppure tra corpora in due lingue diverse (come avviene per la quasi totalità dei progetti presi in considerazione). In questo secondo caso il confronto può avvenire tra testi tradotti e originali oppure tra testi non tradotti in ciascuna delle due lingue. Lo schema Nella figura che segue, adattato da Johansson (1998), riassume i diversi tipi di relazione possibili in una dimensione contrastiva.
Corpora per lo studio della traduzione
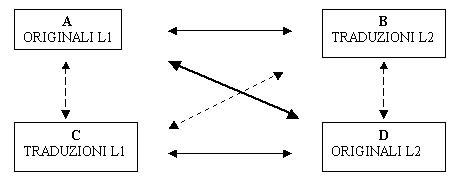
I quadrati rappresentano le diverse possibili componenti di un corpus e le linee i diversi tipi di relazioni possibili. Lo schema prende in considerazione solamente una coppia di lingue, ma potrebbe naturalmente essere esteso ad altre, così come è possibile che un corpus contrastivo comprenda più di una coppia di componenti.
La terminologia al riguardo non è uniforme, ma una distinzione solitamente attuata è quella tra corpora monolingui, corpora bilingui e corpora multilingui. Se questa distinzione è immediatamente intuitiva e funzionale a una categorizzazione ai fini di ricerche puramente linguistiche, essa diviene non sufficientemente specifica quando si entri in una prospettiva traduttiva, in cui è la natura dei testi tradotti o il loro rapporto con testi in un'altra lingua ad essere oggetto di indagine. Altrettanto importante della lingua (una, due o più) in cui sono scritti i testi contenuti nel corpus è lo status di questi testi nei confronti della traduzione. Oltre a "originale" e "traduzione" vi potrebbero essere infatti anche categorie come "adattamento" o "versione", oppure si potrebbe distinguere tra "traduzioni dirette" e "traduzioni indirette" (Toury 1995).
Un primo tipo di corpus, in cui originali in una lingua sono esaminati a fianco di traduzioni verso quella lingua di testi appartenenti allo stesso genere, è denominato da Baker (1993) "comparable corpus", differenziandolo da un "parallel corpus" (originali e traduzioni in un'altra lingua) e da un "multilingual corpus" (testi originali in lingue diverse appartenenti allo stesso genere). Questo tipo di rapporto tra le due componenti del corpus è indicato nella figura corpora per lo studio della traduzione da una linea verticale spezzata. Una distinzione di questo tipo esplicita però solamente la relazione tra le componenti (data dall'opposizione comparabile - parallelo), oppure si limita a indicare che più di una lingua è coinvolta, nel caso di un "multilingual corpus". L'attributo "comparable" è d'altra parte vago: il tipo di confronto a cui ci si riferisce non viene esplicitato, e qualsiasi corpus può essere messo a confronto con qualsiasi altro se chi lo fa trova un buon motivo per farlo. Sono infatti disponibili altri corpora monolingui comparabili come, ad esempio, l'ICE (International Corpus of Englishes) che mette a confronto diverse varietà geografiche dell'inglese. Ci si riferirà comunque a questo tipo di corpus (esemplificato nella figura corpora per lo studio della traduzione dalle linee tratteggiate verticali) come corpus comparabile monolingue, dando per scontato la natura traduttiva di una delle due componenti del corpus. Come accennato, un progetto che utilizza questa tipologia di corpus è l'ECC Project presso la Umist di Manchester (descritto in Laviosa 1998b), nel cui ambito è stato creato un corpus di testi narrativi e giornalistici tradotti verso l'inglese da diverse lingue, che è stato poi messo a confronto con un corpus di testi appartenenti agli stessi generi ma composti originariamente in lingua inglese. L'obiettivo primario del progetto è un'indagine delle caratteristiche generali dei testi tradotti (Baker 1993, 1995).
Un secondo tipo di corpus è quello composto da testi in due o più lingue legati da un rapporto traduttivo, ovvero per cui sia stata identificata una relazione di equivalenza tra i testi nelle diverse lingue. Ad esso ci si riferisce solitamente con il termine "parallel corpus", anche se in alcuni casi si preferisce parlare di "translational corpus" (Lauridsen 1996), "bi-texts" (Harris 1988), o di "core parallel corpus" (Johansson e Hofland 1996) per distinguerlo da un corpus bilingue non contenente traduzioni. In questa tesi, il termine corpus parallelo verrà comunque adottato per brevità, specificando se necessario il numero di lingue coinvolte (se più di due) e la direzionalità. Il tipo di rapporto intercorrente tra le componenti è in questo caso quello esemplificato dalle linee orizzontali nella figura corpora per lo studio della traduzione. Tutti i progetti a cui si è accennato, ad esclusione dell'ECC Project, comprendono o sono basati esclusivamente su questo tipo di corpus. Le lingue (le componenti del corpus) possono essere anche più di due, come nel caso del LINGUA Project, del PEDANT Project o del MULTEXT Project; il rapporto tra le componenti è solitamente direzionale, andando da dei testi di origine a delle traduzioni, ma può anche comportare la presenza di testi nati contemporaneamente come testi originari in più lingue, come è il caso ad esempio del corpus contenente alcuni documenti del parlamento europeo sviluppato nell'ambito del progetto LINGUA.
Si può inoltre avere la compresenza nel corpus di testi originali e in traduzione in ciascuna delle lingue coinvolte, come nel caso del corpus Hansard canadese, in cui gli atti del parlamento possono essere indifferentemente originali o traduzioni in o dal francese o dall'inglese, o dell'ENPC, la cui composizione è schematizzata nella figura corpora per lo studio della traduzione. In quest'ultimo caso, che rende idealmente possibili tutti i tipi di confronto a cui si è accennato, è possibile adottare il termine "reciprocal corpus" proposto da Teubert (1996). Il concetto di corpus reciproco, speculare nelle sue componenti, è in realtà un'astrazione, in quanto la pratica della traduzione riflette situazioni di diseguaglianza linguistica. Ad esempio, Aijmer, Altenberg e Johansson (1996: 79-82) notano come nella costruzione del corpus da utilizzare nel progetto "Text-based contrastive studies in English" messo a punto presso l'università di Lund sia stato difficile ottenere un effettivo equilibrio tra le diverse componenti in quanto non è possibile arrivare ad una vera "reciprocità" in un corpus bilingue generale e questo perchè molti generi testuali vengono spesso tradotti in una sola direzione. Ad esempio, mentre testi di narrativa "popolare" tradotti dall'inglese verso lo svedese abbondano, testi di questo genere tradotti verso l'inglese sono praticamente inesistenti.
Per poter sfruttare al meglio un corpus parallelo è necessaria una procedura di allineamento, che consenta di avere accesso a concordanze parallele, in cui cioè originale e traduzione (o semplicemente testi "coestensivi" in due o più lingue) compaiano come "testo a fronte". Corpora paralleli sono stati utilizzati principalmente nella ricerca terminologica, negli studi sulla traduzione automatica e sulla linguistica contrastiva (cfr. ad esempio Aijmer, Altenberg e Johansson 1996; Sinclair 1996; Johansson e Oksefjiell 1998; Tognini Bonelli 2000), ma possono essere utilizzati anche per analizzare fenomeni traduttivi dal punto di vista della lingua di arrivo o della lingua di partenza. Se il corpus è reciproco o se sono disponibili dei corpora di riferimento monolingui di testi originali (come nel caso del BNC per l'inglese), il confronto può essere esteso al tipo di relazione indicato dalle linee verticali in figura corpora per lo studio della traduzione.
Un terzo tipo di corpus è quello in cui sono messi in relazione testi indipendentemente composti in due o più lingue e appartenenti allo stesso genere, ovvero testi bilingui (o multilingui) comparabili. Nella letteratura in materia questo tipo di corpus è chiamato sia "multilingual corpus" (Baker 1993) che "comparable corpus" (Laffling 1992, Zanettin 1994, Picchi e Peters 1997) alcuni studiosi si sono inoltre riferiti a questo tipo di corpus con il termine "parallel texts" (Snell-Hornby 1988, Nord 1997, Schäffner 1998, anche se in riferimento a un corpus di testi cartacei piuttosto che elettronici).[1] Qui di seguito si userà il termine corpus comparabile bilingue, specificando il numero delle lingue se più di due. Questo tipo di corpus è stato utilizzato per studi contrastivi basati su testi originali in due lingue (ad esempio Snell-Hornby 1987), per la ricerca sull'estrazione di dati terminologici bilingui (ad esempio Laffling 1992) e per la didattica della lingua e della traduzione (ad esempio Gavioli e Zanettin 1997, Maia 1997, Zanettin in corso di pubblicazione). A differenza dei testi paralleli, i testi comparabili non sono allineabili (se lo fossero sarebbero testi paralleli), e questo rende più difficoltoso un uso automatizzato. Alcune proposte per l'elaborazione di procedure automatiche di "sincronizzazione", cioè della ricerca automatica di corrispondenze testuali tra segmenti nelle due lingue, sono state avanzate (Laffling 1992, Peters e Picchi 1998) e verranno discusse in corpus processing, ma al momento non sembrano essere disponibili applicazioni commerciali in grado di automatizzare (parte di) l'estrazione di dati bilingui.
In ambito traduttologico, il confronto tra corpora di testi prodotti originariamente in ciascuna delle lingue da cui o verso cui si traduce è fondamentale in quanto disponendo esclusivamente di corpora di tipo parallelo, ovvero in cui una delle due componenti prese in esame sia composta esclusivamente da testi tradotti (e precisamente dalle traduzioni dei testi che formano l'altra componente del corpus), si otterranno dati esclusivamente relativi a quella varietà di lingua. Il problema non è tanto quello della "qualità" dei testi tradotti, problema affrontabile una volta che siano resi espliciti i criteri che hanno guidato la compilazione del corpus, quanto quelli connessi alla "natura" delle traduzioni (e della traduzione). È stato infatti ipotizzato che nei testi tradotti non vengano espresse appieno le potenzialità della lingua e che essi possano riflettere le idiosincrasie stilistiche dei traduttori (Teubert 1996 : 247, Picchi e Peters 1997, Gellerstam 1996). Secondo l'approccio adottato in questo lavoro le traduzioni sono considerate delle genuine istanze di comunicazione che differiscono dai testi cosiddetti originali "not because they are corrupt in any way but because they function in a different context of production and reception" (Baker in stampa).
I testi tradotti rappresentano una percentuale, in alcuni casi anche notevolmente consistente, dell'intera produzione testuale (scritta ma anche parlata) di una lingua, e contribuiscono alla caratterizzazione delle norme di aspettativa riguardanti la conformazione linguistica e testuale di testi prodotti in quella lingua (comprese le traduzioni). Il maggiore o minore contributo percentuale delle traduzioni sul totale della produzione di determinati prodotti testuali avrà conseguentemente un peso diverso a seconda delle diverse lingue. Si può, ad esempio, supporre che le traduzioni in lingua inglese, che rappresentano il 2% della produzione editoriale di Stati Uniti e Gran Bretagna (Venuti 1995: 12-15), contribuiscano in maniera marginale al formarsi di norme linguistiche in quei paesi, e quindi influiscano sulle aspettative dei lettori di testi tradotti in maniera minore di quanto non facciano le traduzioni in lingua italiana sui lettori di traduzioni in questo paese, dove i testi tradotti costituiscono circa una quarto dell'intera produzione editoriale (Vigini 1999). Sembra quindi lecito chiedersi se un corpus di riferimento generale per l'italiano non dovrebbe comprendere un consistente numero di testi tradotti.[2] Nel caso dell'Italia le aspettative linguistiche non potranno prescindere anche dalle traduzioni, e in particolare dalle traduzioni dall'inglese (un libro su otto).