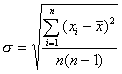Un secondo dato quantitativo relativo al CPR è quello relativo al rapporto tra types e tokens. Per types (o "forme grafiche") si intende le parole diverse tra loro, mentre per tokens ("parole" o "occorrenze") il numero complessivo delle parole. Ad esempio, la frase “sopra la panca la capra campa” contiene cinque types (l’articolo "la" è ripetuto due volte) e sei tokens. Il rapporto tra i due numeri fornisce una misura della varietà lessicale di un testo: quanto maggiore è il numero di types all’interno di un corpus, e quindi la varietà di parole presenti, tanto maggiore sarà lo sforzo richiesto al lettore per la lettura. Il rapporto tra types e tokens, è ottenuto dividendo i primi per i secondi.
Nello scioglilingua sopra riportato il rapporto è di 83,33. Il rapporto type/token varia in base alla lunghezza di un testo: più un testo è lungo, più questo rapporto è destinato a calare rapidamente, dato che il numero di parole nuove cresce ad un ritmo minore di quanto aumenti la frequenza delle parole che si ripetono. Ad esempio, in questo paragrafo il rapporto è di 47,98, cifra ottenuta dividendo il numero di types (le 107 parole diverse fra loro) per il numero di tokens (le 223 parole complessive che compongono il paragrafo) e moltiplicando per mille. Per ottenere una base stabile di comparazione il programma Wordlist permette di eseguire il calcolo su segmenti di testo di lunghezza stabile (ad esempio 1000 parole) e ottenere un dato standardizzato. Un basso valore indica che un numero ristretto di parole si ripete diverse volte nel testo, mentre un valore alto indica che il testo è scarsamente ripetitivo. In altre parole, il rapporto type/token può essere ritenuto un indice della creatività e ricchezza lessicale di un testo.
Il rapporto type/token è uno dei quattro indici identificati da Laviosa (1998b) per misurare la varietà lessicale di un testo, insieme a un valore di "densità lessicale", al rapporto tra parole più frequenti e quelle meno frequenti, e alla lunghezza media delle frasi.[1] Laviosa utilizza questi indici per mettere a confronto la varietà lessicale in un corpus di traduzioni (TEC, cfr. tipi di corpora per lo studio della traduzione) con quella in un corpus comparabile di testi non tradotti, per verificare l’ipotesi che il lessico della lingua in traduzione sia meno vario di quello dei testi originali. I risultati della ricerca portano Laviosa ad identificare quattro caratteristiche centrali (“core patterns”) dell’inglese tradotto rispetto alla lingua dei testi originali: una minore percentuale di parole lessicali, una maggiore proporzione di parole ad alta frequenza, una maggiore percentuale del corpus rappresentata dalle teste di lista (108 parole più frequenti) e un minore numero di lemmi all’interno delle teste di lista.
In questa tesi viene preso in considerazione esclusivamente il rapporto type/token, ai fini di verificare l'applicabilità di questi indici a un corpus parallelo anziché a un corpus comparabile monolingue. La tabella che segue riassume alcuni dati statistici relativi al CPR.
Il
Corpus Parallelo Rushdie: dati statistici
|
Testi |
Tokens |
Types |
T/T Ratio |
T/T std 1000 |
n. di frasi |
|
224.398 |
23.999 |
10,69 |
52,69 |
9.379 |
|
|
214.982 |
17.509 |
8,14 |
49,25 |
8.179 |
|
|
196.646 |
23.536 |
11,97 |
53,47 |
10.338 |
|
|
192.634 |
17.865 |
9,27 |
49,83 |
10.5061 |
|
|
167.630 |
21.843 |
13,03 |
53,63 |
8.245 |
|
|
159.752 |
16.851 |
10,55 |
50,20 |
8.279 |
|
|
107.946 |
15.884 |
14,71 |
53,57 |
4.615 |
|
|
105.488 |
12.074 |
11,45 |
49,79 |
4.573 |
|
|
44.624 |
7.487 |
16,78 |
49,86 |
2.757 |
|
|
43.877 |
5.569 |
12,69 |
45,36 |
2.562 |
|
|
Chekov e Zulu |
5.025 |
1.946 |
38,73 |
55,54 |
507 |
|
Chekov and Zulu |
4.687 |
1.654 |
35,29 |
50,45 |
486 |
|
Totale testi
italiani |
746.269 |
47.762 |
6,40 |
53,09 |
35.891 |
|
Totale testi
inglesi |
721.420 |
33.719 |
4,67 |
49,46 |
34.640 |
Come si può vedere dalla colonna T/T std 1000 (rapporto tra types e tokens standardizzato su una base di mille parole) i testi italiani hanno una percentuale maggiore di quelli inglesi, sia nel loro complesso sia presi singolarmente. Se tale rapporto viene assunto come indice di diversificazione del lessico, questa differenza sembra apparentemente indicare che il lessico delle traduzioni è più vario di quello dei testi inglesi. I due dati non sono però direttamente comparabili, come per quanto riguarda quelli relativi al numero complessivo di parole. Anche in questo caso infatti la differenza potrebbe essere dovuta a differenze strutturali tra le lingue piuttosto che essere una conseguenza del processo di traduzione. Mentre per quanto riguarda la lunghezza dei testi una verifica può provenire dal confronto con traduzioni in più direzioni e in più lingue, il rapporto tra types e tokens deve essere messo in relazione a quelle che sono le norme di aspettativa per ciascuna delle due lingue in esame. In altre parole, i dati riguardanti il rapporto tra types e tokens nei testi inglesi e italiani devono essere rapportati ai dati derivati da due corpora di riferimento, uno per ciascuna delle due lingue. A questo scopo sono stati utilizzati i corpora di riferimento qui descritti, che contengono testi narrativi non tradotti e sono tra loro idealmente comparabili.
La tabella che segue presenta i dati relativi ai quattro corpora messi a confronto.
Corpus parallelo e corpora di riferimento
|
Corpus |
Tokens (numero di
parole) |
Types (numero di
forme) |
Type/token Ratio |
Type/token std 1000 |
|
Romanzi
Rushdie (testi
inglesi) |
721.420 |
33.719 |
4,67 |
49,46 |
|
Corpus di
riferimento inglese |
843.629 |
27.468 |
3,26 |
44,44 |
|
Romanzi
Rushdie (traduzioni
italiane) |
746.269 |
47.762 |
6,40 |
53,09 |
|
Corpus di
riferimento italiano |
856.001 |
58.864 |
6,88 |
49,99 |
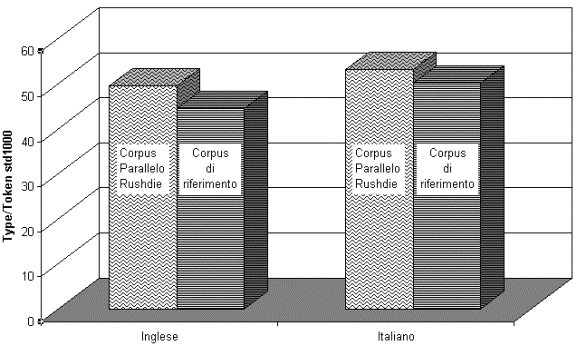
Come si può vedere, la media per il corpus di riferimento italiano (49,99) è di 5,53 punti percentuali più alta di quella del corpus di riferimento inglese, e il lessico dei romanzi di Rushdie, sia in originale che in traduzione, è complessivamente più vario di quanto non lo sia quello dei rispettivi corpora di riferimento. La differenza relativa tra ciascuna delle due coppie di dati è però diversa: mentre la percentuale media per il corpus di riferimento inglese è inferiore di 5, 2 punti alla percentuale media del corpus dei romanzi di Rushdie, la percentuale media del corpus di riferimento italiano è inferiore a quella del corpus di traduzioni di 3,10 punti. Si tratta di una differenza relativa notevole, come si può vedere nella figura che segue:
Varietà lessicale nel corpus parallelo
Per determinare l'attendibilità di questi dati è però necessaria un'ulteriore verifica. Per i corpora di riferimento oltre alla media è necessario tenere conto di un margine di variabilità entro il quale una differenza non è statisticamente rilevante. È necessario cioè stabilire se i dati relativi ai testi di Rushdie si discostino in maniera significativa dalla norma stabilita dal corpus di riferimento oppure se questa differenza sia il frutto di una semplice casualità. A questo scopo è stato calcolata la deviazione standard[2] dal dato medio per ciascuno dei due corpora di riferimento, che si è rivelata inferiore sia per il corpus di riferimento inglese (0,624) sia per il corpus di riferimento italiano (0,885).
Anche tenendo conto di questo margine di tolleranza sia i romanzi di Rushdie che le loro traduzioni italiane si sono quindi rivelati lessicalmente più variati della "norma" determinata dai corpora di riferimento, dato peraltro intuitivamente ipotizzabile in base alle caratteristiche generali di queste opere (cfr. Salman Rushdie).
Il dato relativo alle traduzioni italiane, rapportato a quello relativo al corpus di riferimento in questa lingua o a quello relativo ai testi paralleli inglesi, è in apparente controtendenza rispetto a quanto sinora rilevato: in entrambi i casi infatti il rapporto type/token è rappresentato da una cifra più alta nel corpus di traduzioni. Il lessico delle traduzioni sembrerebbe quindi più diversificato sia rispetto agli originali che rispetto a quanto ci si potrebbe aspettare da un testo di questo tipo originariamente composto in italiano. Se però si prende in considerazione il rapporto tra corpus di riferimento e corpus parallelo relativamente a ciascuna delle due lingue è possibile fornire una diversa interpretazione dei dati. Se è vero infatti che il lessico delle traduzioni italiane dei romanzi di Rushdie è più diversificato della media del corpus di riferimento italiano, è anche vero che lo sono in misura minore di quanto non lo siano i romanzi di Rushdie rispetto alla media del corpus di riferimento inglese. Durante il processo di traduzione si è cioè verificata una consistente semplificazione del lessico, nonostante il lessico delle traduzioni risulti più vario rispetto a un dato medio.
Fin qui si è considerato il corpus parallelo nel suo insieme. È però interessante osservare i dati relativi a ciascuna coppia di testi, rappresentati nella tabella che segue. I testi inglesi sono su sfondo grigio e quelli italiani su sfondo bianco e sono stati ordinati in senso decrescente in base alla differenza tra ciascun testo e il proprio corpus di riferimento.
Varietà lessicale: confronto fra coppie di testi
|
Testi |
Corpus
Parallelo Rusdhie |
Corpus di
riferimento |
Deviazione
standard |
differenza |
|
Chekov and Zulu |
50,45 |
44,44 |
± 0,62 |
+6,01 |
|
Chekov e Zulu |
55,54 |
49,99 |
± 0,88 |
+5,55 |
|
50,20 |
44,44 |
± 0,62 |
+5,76 |
|
|
53,63 |
49,99 |
± 0,88 |
+3,64 |
|
|
49,83 |
44,44 |
± 0,62 |
+5,39 |
|
|
53,47 |
49,99 |
± 0,88 |
+3,48 |
|
|
49,79 |
44,44 |
± 0,62 |
+5,35 |
|
|
53,57 |
49,99 |
± 0,88 |
+3,58 |
|
|
49,25 |
44,44 |
± 0,62 |
+4,81 |
|
|
52,69 |
49,99 |
± 0,88 |
+2,70 |
|
|
45,36 |
44,44 |
± 0,62 |
+0,92 |
|
|
49,86 |
49,99 |
± 0,88 |
-0,13 |
Come si può vedere la differenza tra ciascun testo e corpora di riferimento relativamente al rapporto type/token (standardizzato su base 1000) è, con l'eccezione di Harun e il mar delle storie e di Chekov e Zulu, quasi doppia negli originali rispetto alle traduzioni. Sia Haroun and the Sea of Stories che la sua traduzione italiana si discostano di poco dalla media, e il dato relativo alla traduzione è addirittura negativo, ma non è statisticamente significativo, in quanto inferiore alla deviazione standard. Chekov and Zulu e la sua traduzione si discostano entrambi più degli altri testi dalle rispettive medie di riferimento, con una differenza minima tra i due. Questo dato porterebbe a ipotizzare che in presenza di testi non marcati[3] o estremamente marcati[4] dal punto di vista della varietà lessicale il processo di traduzione non porta ad una semplificazione rilevante. Banalizzando, se un testo è di lettura molto "facile" non viene semplificato in modo rilevante durante il processo di traduzione. Se è di lettura "difficile" viene invece semplificato, a meno che la differenza dalla media non superi una determinata soglia, nel qual caso la semplificazione è minima.
L'interpretazione sopra descritta deve essere naturalmente confermata dall’analisi di altri dati statistici relativi al corpus, ed eventualmente dalla conferma delle ipotesi a partire da altri dati. Il rapporto type/token è solo uno degli indici di varietà lessicale, e deve essere corroborato da dati relativi ad altre simili misurazioni, come ad esempio quelle proposte da Laviosa (1998b). Come si è visto, però, la metodologia utilizzata per un corpus comparabile monolingue non è applicabile direttamente all'analisi di un corpus parallelo, ma deve essere adattata per tenere conto delle due lingue coinvolte.[5] Il valore dell'indagine svolta risiede soprattutto nell'indicazione di una metodologia di analisi per i dati quantitativi di un corpus parallelo.